3. Теоретические основы технологии
Нажатие любой алфавитно-цифровой клавиши на клавиатуре приводит к тому, что в компьютер посылается сигнал в виде двоичного числа, представляющего собой одно из значений кодовой таблицы.
Кодовая таблица — это внутреннее представление символов в компьютере.
В качестве стандарта долгое время использовалась таблица 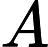
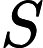
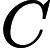
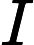 (merican tandard ode for nformational nterchange — Американский стандартный код информационного обмена).
(merican tandard ode for nformational nterchange — Американский стандартный код информационного обмена). Для хранения двоичного кода одного символа выделен 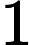 байт
байт 
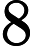 бит. Учитывая, что каждый бит принимает значение или
бит. Учитывая, что каждый бит принимает значение или  , количество возможных сочетаний единиц и нулей равно
, количество возможных сочетаний единиц и нулей равно 



 .
.
байт бит. Учитывая, что каждый бит принимает значение или , количество возможных сочетаний единиц и нулей равно .Значит, с помощью байта можно получить разных двоичных кодовых комбинаций и отобразить с их помощью различных символов.
байта можно получить разных двоичных кодовых комбинаций и отобразить с их помощью различных символов.Эти коды и составляют таблицу .
. Для сокращения записи и удобства пользования этими кодами символов в таблице используют шестнадцатеричную систему счисления, состоящую из символов — цифр и латинских букв: ,  , ,
, , 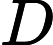 ,
, 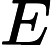 ,
, 
символов — цифр и латинских букв: , , , , , ASCII-коды

Например, латинская буква в таблице представлена шестнадцатеричным кодом — 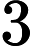 . При нажатии клавиши с буквой в память компьютера записывается код , , представляющий собой двоичный эквивалент шестнадцатеричного числа . Этот код может быть получен путем замены каждой шестнадцатеричной цифры её двоичным представлением. В данном случае цифра заменена кодом , а цифра 3 — кодом . При выводе буквы на экран, компьютер выполняет декодирование: на основании этого двоичного кода строится изображение символа.
. При нажатии клавиши с буквой в память компьютера записывается код , , представляющий собой двоичный эквивалент шестнадцатеричного числа . Этот код может быть получен путем замены каждой шестнадцатеричной цифры её двоичным представлением. В данном случае цифра заменена кодом , а цифра 3 — кодом . При выводе буквы на экран, компьютер выполняет декодирование: на основании этого двоичного кода строится изображение символа.
в таблице представлена шестнадцатеричным кодом — . При нажатии клавиши с буквой в память компьютера записывается код , , представляющий собой двоичный эквивалент шестнадцатеричного числа . Этот код может быть получен путем замены каждой шестнадцатеричной цифры её двоичным представлением. В данном случае цифра заменена кодом , а цифра 3 — кодом . При выводе буквы на экран, компьютер выполняет декодирование: на основании этого двоичного кода строится изображение символа.Любой символ в таблице кодируется с помощью двоичных разрядов или шестнадцатеричных разрядов.
кодируется с помощью двоичных разрядов или шестнадцатеричных разрядов.Стандарт кодирует первые символов от до 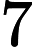 : цифры, буквы латинского алфавита, управляющие символы. Таблица выше отображает кодировку символов в шестнадцатеричной системе счисления.
: цифры, буквы латинского алфавита, управляющие символы. Таблица выше отображает кодировку символов в шестнадцатеричной системе счисления.
кодирует первые символов от до : цифры, буквы латинского алфавита, управляющие символы. Таблица выше отображает кодировку символов в шестнадцатеричной системе счисления.Первые символа являются управляющими и предназначены в основном для передачи команд управления. Их назначение может варьироваться в зависимости от программных и аппаратных средств. Вторая половина кодовой таблицы (от до ) американским стандартом не определена и предназначена для символов национальных алфавитов, псевдографических и некоторых математических символов. В разных странах могут использоваться различные варианты второй половины кодовой таблицы.
символа являются управляющими и предназначены в основном для передачи команд управления. Их назначение может варьироваться в зависимости от программных и аппаратных средств. Вторая половина кодовой таблицы (от до ) американским стандартом не определена и предназначена для символов национальных алфавитов, псевдографических и некоторых математических символов. В разных странах могут использоваться различные варианты второй половины кодовой таблицы.Цифры кодируются по стандарту в двух случаях: при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в двоичный код в соответствии с правилами.
в двух случаях: при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в двоичный код в соответствии с правилами. для двух вариантов кодирования.
для двух вариантов кодирования. При использовании в тексте это число потребует для своего представления байта, поскольку каждая цифра будет представлена своим кодом в соответствии с таблицей . . В шестнадцатеричной системе код будет выглядеть как , в двоичной системе — .
байта, поскольку каждая цифра будет представлена своим кодом в соответствии с таблицей . . В шестнадцатеричной системе код будет выглядеть как , в двоичной системе — . При использовании в вычислениях код этого числа будет получен по специальным правилам перевода и представлен в виде -разрядного двоичного числа , на что потребуется байт.
-разрядного двоичного числа , на что потребуется байт. Стандарт 



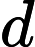
 явился результатом сотрудничества Международной организации по стандартизации (
явился результатом сотрудничества Международной организации по стандартизации (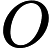 ) с ведущими производителями компьютеров и программного обеспечения. В мире существует живых языков, но только из них являются официальными языками государств. Письменностей используется около , что делает возможным создание универсального стандарта.
) с ведущими производителями компьютеров и программного обеспечения. В мире существует живых языков, но только из них являются официальными языками государств. Письменностей используется около , что делает возможным создание универсального стандарта.
явился результатом сотрудничества Международной организации по стандартизации () с ведущими производителями компьютеров и программного обеспечения. В мире существует живых языков, но только из них являются официальными языками государств. Письменностей используется около , что делает возможным создание универсального стандарта. Для кодирования этих письменностей достаточно -битового диапазона ( байта на символ), то есть диапазона от до . Стандарт занимает в кодовом пространстве свое почетное место в диапазоне от до .
-битового диапазона ( байта на символ), то есть диапазона от до . Стандарт занимает в кодовом пространстве свое почетное место в диапазоне от до . Каждой письменности выделен свой блок кодов. На сегодняшний день кодирование всех живых официальных письменностей считается завершенным: распределено около  позиций из возможных.
позиций из возможных.
позиций из возможных. Кодовая таблица Unicode

Для представления такого разнообразия языков -битового кодирования уже недостаточно, и сегодня уже приступил к освоению -битового пространства кодов (-), ), которое разбито на зон, названных плоскостями.
-битового кодирования уже недостаточно, и сегодня уже приступил к освоению -битового пространства кодов (-), ), которое разбито на зон, названных плоскостями.